Adaptación de Mistral 7B para seguir instrucciones en español
Adaptación de Mistral 7B para seguir instrucciones en español
Use AI to create music with your voice and Leverage the latest in AI technology to supercharge your music.
As the internet continues to develop and grow exponentially, jobs related to the industry do too, particularly those that relate to web design and development.
26 de octubre de 2023

Mistral es un modelo de lenguaje de 7.3 billones de parámetros que ha superado el estado del arte en modelos open-source anteriormente establecido por Llama 2 de Meta, demostrando un rendimiento superior a modelos que triplican su tamaño y posicionándose como el modelo de lenguaje open-source más eficiente hasta la fecha.
Aprovechando esta sólida base, en Clibrain nos hemos centrado en una brecha que estamos especialmente preparados para resolver: optimizarlo para el mundo hispanohablante. Mediante un riguroso proceso de evaluación podemos confirmar que no solo hemos conservado el excepcional rendimiento de Mistral, sino que también hemos garantizado su plena funcionalidad en español.
Desbancando a los mejores modelos open-source hasta la fecha
Hasta la aparición de este nuevo modelo, Meta ocupada los mejores puestos en las evaluaciones de modelos de lenguaje open-source con Llama 2, que fue presentado en tres tamaños (7B, 13B, 70B).
Mistral 7B ha conseguido superar a la versión de 13B de Llama 2 (casi el doble de tamaño) en todo tipo de benchmarks. Además, es también superior a LLama 1 en su versión de 34B de parámetros en código, matemáticas y razonamiento.
Esto demuestra la gran eficiencia de Mistral 7B, mejorando el rendimiento de modelos con un mayor número de parámetros. Esta eficiencia permite hacer uso de menos recursos computacionales, sin que el rendimiento se vea comprometido.
Rapidez y eficiencia en su máximo exponente
Mediante el uso de diferentes mecanismos de atención, Mistral consigue una baja latencia y poder manejar secuencias de texto más largas (un mayor contexto).
El mecanismo Sliding Window Attention (SWA) (Child et al., Beltagy et al.) permite manejar secuencias de longitud considerable con facilidad. Aprovechando las capas apiladas de un transformador para atender a los tokens en el pasado más allá del tamaño de la ventana, proporciona a las capas superiores acceso a la información más atrás en el tiempo.
La técnica Grouped Query Attention (GQA) (Ainslie et al.) permite inferencias más rápidas, procesando las queries de forma más eficiente. Las consultas se agrupan en función de su similitud y se procesan juntas. Esto permite que el modelo haga predicciones más rápidamente y haciendo uso de menos recursos.
Juntos, GQA y SWA permiten a Mistral 7B manejar longitudes de hasta 16.000 tokens con baja latencia y utilizando un 50% menos de memoria.
Mistral 7B, ahora en español
Desde Clibrain tenemos una misión clara: desarrollar inteligencia artificial para los más de 600 millones de hispanohablantes en el mundo. Como con nuestras adaptaciones y lanzamientos anteriores, queremos que la comunidad hispanohablante pueda beneficiarse de los últimos avances que se realizan en esta tecnología, dominada por el inglés.
Por ello, hemos realizado una adaptación de Mistral 7B mediante técnicas de fine-tuning para seguir instrucciones en español y así, permitir que la comunidad hispanohablante interactúe con el modelo.
Conseguimos mantener el rendimiento original (on-pair)
Haciendo uso de la técnica de evaluación MT Bench (Zheng et al.), hemos comparado los resultados que ofrece el modelo original de Mistral adaptado para instrucciones, Mistral 7B Instruct, y nuestra adaptación para seguir instrucciones en español.
En la evaluación (MT Bench en español), nuestra adaptación consigue una marca de 6,84, comparada con 7,05 del modelo original. No obstante, el modelo de Mistral puede responder en inglés u otros idiomas al interactuar con instrucciones en español. Con nuestra adaptación conseguimos que hable español en el 100% de las situaciones, manteniendo el rendimiento original (on-pair).
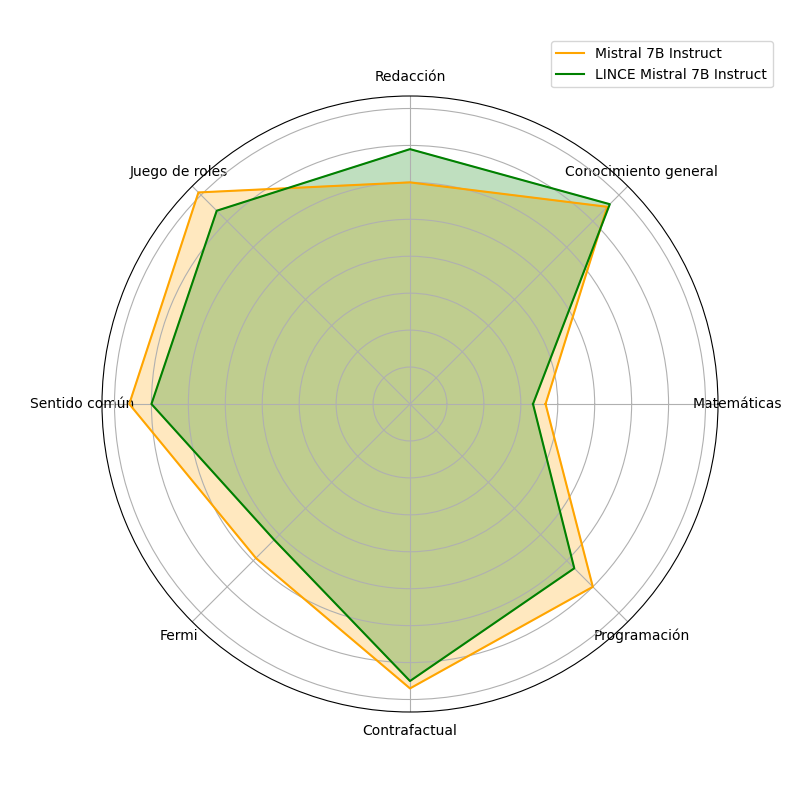
A la hora de analizar el rendimiento de los dos modelos de lenguaje en diferentes categorías (capabilities), nuestra adaptación al español destaca por una mejor capacidad de redacción, donde el control del idioma es fundamental.
Recursos y links de descarga
La adaptación de Mistral 7B, junto con el resto de nuestros modelos open-source, disponibles de forma gratuita en hf.co/clibrain.
Mistral es un modelo de lenguaje de 7.3 billones de parámetros que ha superado el estado del arte en modelos open-source anteriormente establecido por Llama 2 de Meta, demostrando un rendimiento superior a modelos que triplican su tamaño y posicionándose como el modelo de lenguaje open-source más eficiente hasta la fecha.
Aprovechando esta sólida base, en Clibrain nos hemos centrado en una brecha que estamos especialmente preparados para resolver: optimizarlo para el mundo hispanohablante. Mediante un riguroso proceso de evaluación podemos confirmar que no solo hemos conservado el excepcional rendimiento de Mistral, sino que también hemos garantizado su plena funcionalidad en español.
Desbancando a los mejores modelos open-source hasta la fecha
Hasta la aparición de este nuevo modelo, Meta ocupada los mejores puestos en las evaluaciones de modelos de lenguaje open-source con Llama 2, que fue presentado en tres tamaños (7B, 13B, 70B).
Mistral 7B ha conseguido superar a la versión de 13B de Llama 2 (casi el doble de tamaño) en todo tipo de benchmarks. Además, es también superior a LLama 1 en su versión de 34B de parámetros en código, matemáticas y razonamiento.
Esto demuestra la gran eficiencia de Mistral 7B, mejorando el rendimiento de modelos con un mayor número de parámetros. Esta eficiencia permite hacer uso de menos recursos computacionales, sin que el rendimiento se vea comprometido.
Rapidez y eficiencia en su máximo exponente
Mediante el uso de diferentes mecanismos de atención, Mistral consigue una baja latencia y poder manejar secuencias de texto más largas (un mayor contexto).
El mecanismo Sliding Window Attention (SWA) (Child et al., Beltagy et al.) permite manejar secuencias de longitud considerable con facilidad. Aprovechando las capas apiladas de un transformador para atender a los tokens en el pasado más allá del tamaño de la ventana, proporciona a las capas superiores acceso a la información más atrás en el tiempo.
La técnica Grouped Query Attention (GQA) (Ainslie et al.) permite inferencias más rápidas, procesando las queries de forma más eficiente. Las consultas se agrupan en función de su similitud y se procesan juntas. Esto permite que el modelo haga predicciones más rápidamente y haciendo uso de menos recursos.
Juntos, GQA y SWA permiten a Mistral 7B manejar longitudes de hasta 16.000 tokens con baja latencia y utilizando un 50% menos de memoria.
Mistral 7B, ahora en español
Desde Clibrain tenemos una misión clara: desarrollar inteligencia artificial para los más de 600 millones de hispanohablantes en el mundo. Como con nuestras adaptaciones y lanzamientos anteriores, queremos que la comunidad hispanohablante pueda beneficiarse de los últimos avances que se realizan en esta tecnología, dominada por el inglés.
Por ello, hemos realizado una adaptación de Mistral 7B mediante técnicas de fine-tuning para seguir instrucciones en español y así, permitir que la comunidad hispanohablante interactúe con el modelo.
Conseguimos mantener el rendimiento original (on-pair)
Haciendo uso de la técnica de evaluación MT Bench (Zheng et al.), hemos comparado los resultados que ofrece el modelo original de Mistral adaptado para instrucciones, Mistral 7B Instruct, y nuestra adaptación para seguir instrucciones en español.
En la evaluación (MT Bench en español), nuestra adaptación consigue una marca de 6,84, comparada con 7,05 del modelo original. No obstante, el modelo de Mistral puede responder en inglés u otros idiomas al interactuar con instrucciones en español. Con nuestra adaptación conseguimos que hable español en el 100% de las situaciones, manteniendo el rendimiento original (on-pair).
A la hora de analizar el rendimiento de los dos modelos de lenguaje en diferentes categorías (capabilities), nuestra adaptación al español destaca por una mejor capacidad de redacción, donde el control del idioma es fundamental.
Recursos y links de descarga
La adaptación de Mistral 7B, junto con el resto de nuestros modelos open-source, disponibles de forma gratuita en hf.co/clibrain.
Mistral es un modelo de lenguaje de 7.3 billones de parámetros que ha superado el estado del arte en modelos open-source anteriormente establecido por Llama 2 de Meta, demostrando un rendimiento superior a modelos que triplican su tamaño y posicionándose como el modelo de lenguaje open-source más eficiente hasta la fecha.
Aprovechando esta sólida base, en Clibrain nos hemos centrado en una brecha que estamos especialmente preparados para resolver: optimizarlo para el mundo hispanohablante. Mediante un riguroso proceso de evaluación podemos confirmar que no solo hemos conservado el excepcional rendimiento de Mistral, sino que también hemos garantizado su plena funcionalidad en español.
Desbancando a los mejores modelos open-source hasta la fecha
Hasta la aparición de este nuevo modelo, Meta ocupada los mejores puestos en las evaluaciones de modelos de lenguaje open-source con Llama 2, que fue presentado en tres tamaños (7B, 13B, 70B).
Mistral 7B ha conseguido superar a la versión de 13B de Llama 2 (casi el doble de tamaño) en todo tipo de benchmarks. Además, es también superior a LLama 1 en su versión de 34B de parámetros en código, matemáticas y razonamiento.
Esto demuestra la gran eficiencia de Mistral 7B, mejorando el rendimiento de modelos con un mayor número de parámetros. Esta eficiencia permite hacer uso de menos recursos computacionales, sin que el rendimiento se vea comprometido.
Rapidez y eficiencia en su máximo exponente
Mediante el uso de diferentes mecanismos de atención, Mistral consigue una baja latencia y poder manejar secuencias de texto más largas (un mayor contexto).
El mecanismo Sliding Window Attention (SWA) (Child et al., Beltagy et al.) permite manejar secuencias de longitud considerable con facilidad. Aprovechando las capas apiladas de un transformador para atender a los tokens en el pasado más allá del tamaño de la ventana, proporciona a las capas superiores acceso a la información más atrás en el tiempo.
La técnica Grouped Query Attention (GQA) (Ainslie et al.) permite inferencias más rápidas, procesando las queries de forma más eficiente. Las consultas se agrupan en función de su similitud y se procesan juntas. Esto permite que el modelo haga predicciones más rápidamente y haciendo uso de menos recursos.
Juntos, GQA y SWA permiten a Mistral 7B manejar longitudes de hasta 16.000 tokens con baja latencia y utilizando un 50% menos de memoria.
Mistral 7B, ahora en español
Desde Clibrain tenemos una misión clara: desarrollar inteligencia artificial para los más de 600 millones de hispanohablantes en el mundo. Como con nuestras adaptaciones y lanzamientos anteriores, queremos que la comunidad hispanohablante pueda beneficiarse de los últimos avances que se realizan en esta tecnología, dominada por el inglés.
Por ello, hemos realizado una adaptación de Mistral 7B mediante técnicas de fine-tuning para seguir instrucciones en español y así, permitir que la comunidad hispanohablante interactúe con el modelo.
Conseguimos mantener el rendimiento original (on-pair)
Haciendo uso de la técnica de evaluación MT Bench (Zheng et al.), hemos comparado los resultados que ofrece el modelo original de Mistral adaptado para instrucciones, Mistral 7B Instruct, y nuestra adaptación para seguir instrucciones en español.
En la evaluación (MT Bench en español), nuestra adaptación consigue una marca de 6,84, comparada con 7,05 del modelo original. No obstante, el modelo de Mistral puede responder en inglés u otros idiomas al interactuar con instrucciones en español. Con nuestra adaptación conseguimos que hable español en el 100% de las situaciones, manteniendo el rendimiento original (on-pair).
A la hora de analizar el rendimiento de los dos modelos de lenguaje en diferentes categorías (capabilities), nuestra adaptación al español destaca por una mejor capacidad de redacción, donde el control del idioma es fundamental.
Recursos y links de descarga
La adaptación de Mistral 7B, junto con el resto de nuestros modelos open-source, disponibles de forma gratuita en hf.co/clibrain.
Mistral es un modelo de lenguaje de 7.3 billones de parámetros que ha superado el estado del arte en modelos open-source anteriormente establecido por Llama 2 de Meta, demostrando un rendimiento superior a modelos que triplican su tamaño y posicionándose como el modelo de lenguaje open-source más eficiente hasta la fecha.
Aprovechando esta sólida base, en Clibrain nos hemos centrado en una brecha que estamos especialmente preparados para resolver: optimizarlo para el mundo hispanohablante. Mediante un riguroso proceso de evaluación podemos confirmar que no solo hemos conservado el excepcional rendimiento de Mistral, sino que también hemos garantizado su plena funcionalidad en español.
Desbancando a los mejores modelos open-source hasta la fecha
Hasta la aparición de este nuevo modelo, Meta ocupada los mejores puestos en las evaluaciones de modelos de lenguaje open-source con Llama 2, que fue presentado en tres tamaños (7B, 13B, 70B).
Mistral 7B ha conseguido superar a la versión de 13B de Llama 2 (casi el doble de tamaño) en todo tipo de benchmarks. Además, es también superior a LLama 1 en su versión de 34B de parámetros en código, matemáticas y razonamiento.
Esto demuestra la gran eficiencia de Mistral 7B, mejorando el rendimiento de modelos con un mayor número de parámetros. Esta eficiencia permite hacer uso de menos recursos computacionales, sin que el rendimiento se vea comprometido.
Rapidez y eficiencia en su máximo exponente
Mediante el uso de diferentes mecanismos de atención, Mistral consigue una baja latencia y poder manejar secuencias de texto más largas (un mayor contexto).
El mecanismo Sliding Window Attention (SWA) (Child et al., Beltagy et al.) permite manejar secuencias de longitud considerable con facilidad. Aprovechando las capas apiladas de un transformador para atender a los tokens en el pasado más allá del tamaño de la ventana, proporciona a las capas superiores acceso a la información más atrás en el tiempo.
La técnica Grouped Query Attention (GQA) (Ainslie et al.) permite inferencias más rápidas, procesando las queries de forma más eficiente. Las consultas se agrupan en función de su similitud y se procesan juntas. Esto permite que el modelo haga predicciones más rápidamente y haciendo uso de menos recursos.
Juntos, GQA y SWA permiten a Mistral 7B manejar longitudes de hasta 16.000 tokens con baja latencia y utilizando un 50% menos de memoria.
Mistral 7B, ahora en español
Desde Clibrain tenemos una misión clara: desarrollar inteligencia artificial para los más de 600 millones de hispanohablantes en el mundo. Como con nuestras adaptaciones y lanzamientos anteriores, queremos que la comunidad hispanohablante pueda beneficiarse de los últimos avances que se realizan en esta tecnología, dominada por el inglés.
Por ello, hemos realizado una adaptación de Mistral 7B mediante técnicas de fine-tuning para seguir instrucciones en español y así, permitir que la comunidad hispanohablante interactúe con el modelo.
Conseguimos mantener el rendimiento original (on-pair)
Haciendo uso de la técnica de evaluación MT Bench (Zheng et al.), hemos comparado los resultados que ofrece el modelo original de Mistral adaptado para instrucciones, Mistral 7B Instruct, y nuestra adaptación para seguir instrucciones en español.
En la evaluación (MT Bench en español), nuestra adaptación consigue una marca de 6,84, comparada con 7,05 del modelo original. No obstante, el modelo de Mistral puede responder en inglés u otros idiomas al interactuar con instrucciones en español. Con nuestra adaptación conseguimos que hable español en el 100% de las situaciones, manteniendo el rendimiento original (on-pair).
A la hora de analizar el rendimiento de los dos modelos de lenguaje en diferentes categorías (capabilities), nuestra adaptación al español destaca por una mejor capacidad de redacción, donde el control del idioma es fundamental.
Recursos y links de descarga
La adaptación de Mistral 7B, junto con el resto de nuestros modelos open-source, disponibles de forma gratuita en hf.co/clibrain.